Nvidia’s new chip is not a software upgrade. So why is everyone treating it like one?
- 15 min read
- 1,056
- Published 22 May 2026

At GTC 2026 in March — the world’s premier AI developer conference — Nvidia founder Jensen Huang took the stage and unveiled what the company is calling its most significant hardware leap in years. Within hours, Indian IT stocks went into a near-vertical fall. TCS, Infosys, and Coforge all slipped close to 6%. Nifty IT dropped nearly 1%. Most IT stocks are now trading around their 52-week lows, some lower.
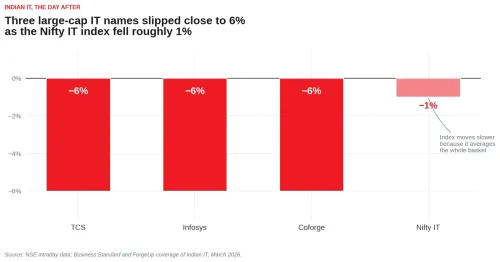
The fall was concentrated in the large IT names. The index, weighted across many sectors, moved less.
The most common reaction we heard was a shrug. “This is like the Claude upgrade a few weeks ago,” people said. “Markets panic, then they recover.” We think that comparison misses something important. This is not a software upgrade dressed in hardware clothing. Something more structural is happening — and to understand what, we need to start at the beginning.
What AI has actually been doing all along
Whenever most of us think about AI, we imagine software. You open an app, type a question, and get an answer. It feels like magic, but the mechanics are fairly straightforward once you see them.
Say you ask an AI to write a blog on the top ten destinations to visit in Himachal Pradesh under Rs 40,000. Here is what actually happens: the AI reads through millions of travel blogs and books, filters destinations by budget, ranks them by popularity, stores that ranking, and then produces a blog in the style of the best content it has encountered. Ask it to write Java code and it does the same thing — scans the internet, learns the patterns, stores the logic, delivers the output. In both cases, it read, it learnt, it applied.
The reading and learning part has a name: training. Think of it like attending a course — intensive, occasional, expensive. The applying part — where AI responds to your actual prompts, every day — is called inference. This is what you use every time you open ChatGPT or Gemini. For years, most of the investment and noise in AI hardware was about training — building bigger models, faster. But training is invisible to the end user. What actually creates value, what determines how useful an AI tool is, is inference. And that is exactly what is changing now.

Two phases of AI work. Training is rare and expensive; inference happens every time the model is used.
The engine room: why a gaming chip runs the world’s AI
To understand why Nvidia’s announcement matters, you need a basic picture of what is happening inside the machines that run AI. There are two key components: the CPU and the GPU, and they do very different things.
A CPU — the Central Processing Unit — is the brain of a traditional computer. It handles logic, manages the operating system, executes instructions one after another in careful sequence. Think of it as a senior manager: brilliant at handling complex, varied situations, but working through one thing at a time. It is what runs your spreadsheets, your databases, your operating system.
A GPU — the Graphics Processing Unit — was built for gaming and video rendering. Its superpower is parallel computation: doing thousands of smaller calculations simultaneously. While a CPU might have 8 to 16 cores, a modern GPU has thousands. Think of it as a vast workforce of junior employees, each handling a small, simple task, all at once. This makes GPUs ideal for the matrix mathematics that sits at the heart of AI — enormous grids of numbers being multiplied together at high speed. This is fundamentally a parallel processing job, not a sequential one. It is why Nvidia, a gaming chip company, became the backbone of the AI revolution.

The architectural difference made visible: few powerful cores versus many small ones working in parallel.
The problem, for years, was that CPUs and GPUs had to communicate like colleagues emailing each other — back and forth, potential delays, unnecessary handoffs. What Nvidia has been progressively building is something closer to two chefs working side by side in the same kitchen, passing ingredients hand to hand in real time.
This unified architecture — where CPUs and GPUs act as peers within a single integrated platform rather than separate components that talk to each other — is not new. But with each generation, Nvidia has made it tighter, faster, and more efficient. The overhead drops. The throughput rises. The cost per operation falls. And this is the foundational reason why newer Nvidia chips can run AI inference so much faster than their predecessors.
What has actually changed: the H100 versus Blackwell
The previous flagship was the H100 — the chip that powered most of the world’s enterprise AI services through the boom years. It carries 80 billion transistors and was designed primarily with training in mind. Capable at inference, but not purpose-built for it. Blackwell changes that entirely.
The numbers are striking. Blackwell packs 208 billion transistors — more than 2.5 times the density of the H100. Inference speed, depending on the workload, is roughly 30 times faster. Training speed for large language models is approximately 2.5 times faster. A new dedicated decompression engine accelerates AI training by about 6 times on its own. And energy efficiency for large-scale inference improves by up to 25 times — meaning dramatically more output per unit of electricity consumed.
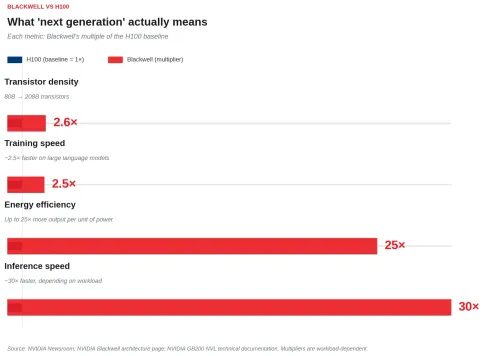
Inference speed and energy efficiency dwarf the other improvements — the article's central point.
What that means in practice: tasks that required a whole cluster of H100 chips can now be handled by far fewer Blackwell chips, at lower energy cost, with faster results. For a company running AI at scale, that translates directly into a lower cost per query. And a lower cost per query changes the commercial logic for deploying AI across more applications, more users, and more industries than were viable before.
The H100 was a remarkable chip. Blackwell makes it look like a transitional product.
And then there is Rubin
Rubin is Nvidia’s next generation — announced as the roadmap beyond Blackwell, but not yet shipping. What Rubin is designed to do is push the CPU-GPU integration further still. If Blackwell brought the two chefs closer together in the kitchen, Rubin is designed to make them almost indistinguishable — a fully unified processing environment where the distinction between sequential and parallel computation begins to blur. The goal is to squeeze out the remaining communication overhead, enabling even faster inference at even lower energy cost per token.

The architectural arc. Each generation tightens the integration between the CPU and the GPU.
Why cheaper inference changes everything
The domino effect here is not complicated, but it is worth stating clearly. More efficient chips make inference cheaper to run. Cheaper inference means more companies can afford to deploy AI — not just the large enterprises that have been doing it already, but mid-market companies, smaller startups, individual workflows. Once adoption is wide enough, tasks that required human labour — repetitive, rule-based, high-volume — become viable candidates for automation. At that point, AI stops being a tool that some organisations use. It becomes infrastructure that everyone uses.
Think of the time when electricity became universally available at the end of the 19th century, it did not merely improve existing industries. It reorganised them. Factories restructured around electric motors. New industries — entertainment, telecommunications, mass media — became possible for the first time. The chip is the generator. The question is what gets built on top of it.
Who is exposed, and who is not
The sectors that face pressure are the ones most dependent on the current model of human-delivered, time-billed work. IT services, where a significant portion of billable hours come from repetitive maintenance, testing, and lower-complexity coding, face the most direct pressure. BPO and KPO businesses, where customer support and knowledge processing are the core product, will find AI agents capable of handling more of that work. Basic SaaS tools — the ones that exist to organise, sort, or present data without much intelligence — will increasingly be replaced by AI-native alternatives that do the same job better with less configuration.
The sectors that benefit are the ones that sit upstream. Cloud providers — Microsoft, Amazon, Google — need to run all this AI somewhere, and demand for their infrastructure grows with adoption. Data centres face a surge in demand for physical infrastructure: servers, cooling systems, power supplies, land. Semiconductor companies across the supply chain benefit from higher volumes and more complex designs. And companies that are building natively on AI infrastructure — rather than trying to retrofit it onto existing models — are better placed than those trying to manage the transition from a defensive position.

Cheaper inference creates two opposite force fields across sectors.
The role picture is more nuanced than the headlines suggest. Roles are not simply disappearing. They are changing character. Coding from scratch gives way to directing AI that codes. Data entry gives way to managing AI that processes data. The shift, broadly, is from execution to supervision to design — from doing the work to specifying and overseeing the systems that do the work. Coders become AI specialists. Writers become content managers. IT managers become data centre managers. Whether the people currently doing the execution-layer work can make that transition, and at what pace, is the real question.
Where does India actually stand?
India’s position in this shift is genuinely mixed, and we think it is worth being honest about both sides rather than landing on easy optimism or easy alarm.
The strengths are real. India’s engineering workforce has navigated every major technology shift of the last four decades — mainframes, the internet, cloud computing — and found a place in each new order. That adaptability is not trivial. Indian IT firms have deep integration with major global clients across every industry, built over three decades of relationship-intensive work. They have the operational scale to deploy AI solutions at speed when the client demand is there. And the growing startup ecosystem, along with the Rs 76,000 crore Indian Semiconductor Mission and associated incentive schemes, signals that policy attention to the hardware layer is no longer absent.
The gaps are also real. Semiconductor manufacturing is genuinely new for India. Reaching the fabrication productivity of Taiwan or South Korea is a decade-long project at minimum, not a near-term ambition. The hardware ecosystem — the fabs, the specialised supply chains, the process engineers — is nascent in a way that cannot be resolved quickly regardless of policy intent. And the capital requirements for serious semiconductor manufacturing are large enough that the number of Indian companies that can participate without sustained institutional backing is very small.
The more interesting question is whether India needs to compete on those terms at all. Taiwan built a fabrication-centred semiconductor industry because of specific historical and geopolitical conditions that do not apply to India. The more realistic paths are different. Fabless chip design — designing chips without owning fabrication facilities — is an area where India already has genuine engineering depth. The work is knowledge-intensive and software-adjacent, which makes it a natural fit for a workforce that has spent three decades building its identity around exactly those skills. Back-end semiconductor services — packaging, testing, and assembly — require significantly less capital than fabrication but face growing global demand as chip volumes rise, making them a more accessible entry point into the hardware value chain. And world-class AI software built on top of global infrastructure is arguably the area where India’s combination of engineering talent, English-language capability, and existing enterprise relationships is most potent — and where the advantage is already most visible.
The genuine threat is not Nvidia specifically. It is fragmentation. Amazon, Google, and Meta are all building custom chips to reduce dependence on Nvidia. As the chip market diversifies, so will the software ecosystems built on top of it. Indian IT firms will need to be fluent across multiple architectures and toolchains rather than optimising for a single dominant platform. That is a harder problem than it sounds, and the window for positioning ahead of that fragmentation is not indefinitely open.
What we are actually watching for
The Nifty IT fall made the familiar fears loud again: billable hours collapsing, labour cost advantages eroding, legacy ERP systems going the way of the fax machine. Some of those fears have merit. Some are overstated. Honestly, we are not sure of the proportions yet, and we would be sceptical of anyone who claims certainty.
What we do think is that the stock price reaction, in the days immediately following an AI hardware announcement, is almost certainly the wrong thing to watch. Markets are pricing anxiety, not outcomes. The actual signal is slower and quieter: how Indian IT companies describe AI in their earnings calls, whether it is still a feature being added or has become the core product thesis. Where they are hiring. Whether new partnerships are being formed with AI-native companies or whether the old model is being defended. How capex is being allocated.
Those are the things that will tell you whether India’s IT sector is adapting to this shift or being moved by it. We do not know the answer yet. But the data will start to arrive, and we will be watching.
Sources & references
-
NVIDIA GTC 2026 keynote announcement: NVIDIA Corporation press release, 3 March 2026. nvidianews.nvidia.com — context for the keynote referenced in the lede.
-
NVIDIA GTC 2026 keynote, on demand: NVIDIA Corporation, March 2026. nvidia.com/gtc/keynote — primary source for Jensen Huang's GTC announcement.
-
NVIDIA Blackwell platform official launch: NVIDIA Corporation press release. nvidianews.nvidia.com — primary source for 208 billion transistors, up to 25× cost and energy reduction, and up to 30× performance increase for LLM inference relative to H100.
-
NVIDIA Blackwell architecture: NVIDIA Corporation product page. nvidia.com/en-us/data-center/technologies/blackwell-architecture — architectural detail on the dual-die design and 4NP process node.
-
NVIDIA GB200 NVL Multi-Node Tuning Guide: NVIDIA Corporation technical documentation. docs.nvidia.com — reference for the dedicated decompression engine and the second-generation Transformer Engine.
-
NVIDIA GTC 2026 live coverage: NVIDIA Blog, March 2026. blogs.nvidia.com/blog/gtc-2026-news — rolling coverage including Vera Rubin and roadmap announcements.
-
NVIDIA GTC 2026 keynote: Vera Rubin GPUs and CPUs. Tom's Hardware live blog, 16 March 2026. tomshardware.com — third-party coverage of the Rubin roadmap announcement referenced in the article.
-
About SemiconIndia Programme: India Semiconductor Mission, Ministry of Electronics & Information Technology, Government of India. ism.gov.in — primary source for the ₹76,000 crore outlay of the India Semiconductor Mission.
-
India Semiconductor Mission 2.0: Press Information Bureau, Government of India, 7 February 2026. pib.gov.in — current status of the Mission, project approvals, and the Budget 2026–27 expansion.
-
Indian IT sector analysis 2026: a deep dive into valuation. ICICIdirect Research, March 2026. icicidirect.com — context on the broader 2026 Nifty IT correction and AI-led deflation expectations.
-
Nifty IT Index hits 30-month low in 2026: sentiment-driven fall or structural shift? Bigul market analysis, April 2026. bigul.co — analyst commentary on Nifty IT constituent moves.
-
Nifty IT index falls 2% — AI disruption hits IT stocks: ForgeUp news, 17 March 2026. forgeup.in — intraday coverage of the post-GTC IT sell-off referenced in the lede.
-
NSE intraday market data: National Stock Exchange of India. nseindia.com — primary source for stock and index moves cited in the article.
The content in this blog is intended purely for educational purposes. Any securities or mutual funds referenced are illustrative in nature and do not constitute a recommendation or endorsement by Kotak Neo. Investors are encouraged to assess their own financial situation and seek professional advice before making any investment decisions. For compliance T&C and disclaimers, Visit https://www.kotakneo.com/disclaimer/
0 people liked this article.








